
수행기록퀘스트6
첨부파일 내용: fw, model소스, final_report
작성한 Fw에서 좋은 결과를 도출하지 못하여 동영상은 제작하지 못했습니다..
Quest6 주제 : MFCC를 이용한 소리 인식기 구현 ( 작성: TIEL)
소개 : 음성의 주요 성분을 압축한 데이터들을 학습하여 단어들을 인식하는 연구들이 최근에 많이 진행되어 왔습니다. 이에 대한 보드에서의 검증을 진행해 보고자 합니다.
- HW및 SW 정보
HW: 제공받은 보드 (B-L475-IOT01-A)
SW: Python(3.6),Keras(2.2.4),Librosa
- 학습에 이용한 데이터
ESC-10 dataset.
Download link : https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/YDEPUT
ESC-10 Dataset 구성
- 학습 모델
- CNN 모델
- 코드
- CNN 모델
.png)
(40,1) 배열 샘플 입력치에 대해서 1차원 Convolution을 합니다. Kernel 사이즈는 3개, 커널(필터) 개수는 64개로 시작합니다. Relu 활성화 함수를 모두 사용합니다. 두 번째 층에서도 커널개수 사이즈 동일합니다. 세번째에서는 maxpool을 통해 사이즈를 줄입니다. 그리고 몇 개의 층을 더 취하고 나서 마지막에 dense층 으로 마무리 합니다. 출력은 10개의 출력에 대해 softmax 활률값입니다.
위 모델을 적용하여 compile 및 학습을 수행결과는 다음과 같았습니다.
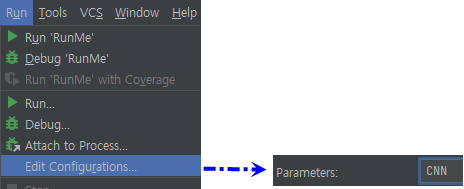
참고로 모델 소스에 CNN모델과 MLP모델 두 가지가 들어 있는데 CNN을 설정하려면 인자로 CNN을 입력해 주셔야 build가 됩니다. pyCharm에서 인자를 입력해 주기 위해서는 아래와 같이 입력해 주시면 됩니다.
Extracting features..
Extracting file dataset\001 - Dog bark\1-100032-A.ogg
Extracting file dataset\001 - Dog bark\1-110389-A.ogg
………
……
Extracting file dataset\010 - Fire crackling\5-215658-A.ogg
Extracting file dataset\010 - Fire crackling\5-215658-B.ogg
Training..
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv1d (Conv1D) (None, 38, 64) 256
conv1d_1 (Conv1D) (None, 36, 64) 12352
max_pooling1d (MaxPooling1D (None, 12, 64) 0
)
conv1d_2 (Conv1D) (None, 10, 128) 24704
global_average_pooling1d (G (None, 128) 0
lobalAveragePooling1D)
dropout (Dropout) (None, 128) 0
dense (Dense) (None, 10) 1290
activation (Activation) (None, 10) 0
=================================================================
Total params: 38,602
Trainable params: 38,602
Non-trainable params: 0
_________________________________________________________________
None
training for 100 epochs with batch size 32
Epoch 1/100
10/10 [==============================] - 1s 21ms/step - loss: 2.3986 - accuracy: 0.1375 - val_loss: 1.9568 - val_accuracy: 0.3375
Epoch 2/100
10/10 [==============================] - 0s 6ms/step - loss: 1.8940 - accuracy: 0.3406 - val_loss: 1.6789 - val_accuracy: 0.5375
……
….
Epoch 99/100
10/10 [==============================] - 0s 6ms/step - loss: 0.2022 - accuracy: 0.9375 - val_loss: 0.9739 - val_accuracy: 0.8000
Epoch 100/100
10/10 [==============================] - 0s 6ms/step - loss: 0.1747 - accuracy: 0.9656 - val_loss: 0.9047 - val_accuracy: 0.8000
Saving model to disk
3/3 [==============================] - 0s 2ms/step - loss: 0.9047 - accuracy: 0.8000
Test loss 0.9046648144721985
Test accuracy 80.0000011920929
100번의 학습이후 정확도 80%가 나왔습니다
학습후 나온 파라미터를 h5파일로 저장후 Cube.ai에서 코드를 생성하면 됩니다.
- Fw 작성
- HW 체크
펌웨어 수정에 앞서 어떤 부분이 Mic인지 확인해 보겠습니다.
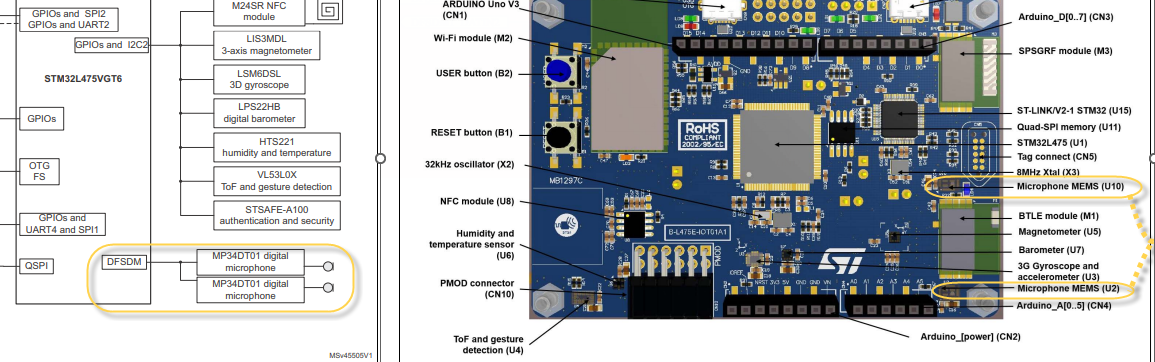
실제 보드에서 위 오렌지 표시된 부분이 mic칩셋이라고 합니다.
mcu에서 DFSDM 기능으로 연결합니다.
.png)
(매뉴얼에 기록된 DFSDM1 핀 연결에 대한 설명)
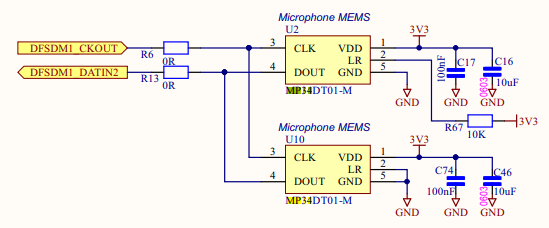
(Mic 칩 연결 회로도)
.png)
(mcu 핀 정보)
4.2 FW 작업
Cube.Ai의 버전은 7.20을 사용하였습니다.
그래서 Sensing1 펌웨어를 그대로 사용할 수 없기에 Cube.Ai에서 생성한 코드에
Mic칩 동작을 이식하는 작업을 수행하였습니다.
펌웨어 작업에 앞서 MFCC에 대해서 정리해 보았습니다
Audio 신호에서 특징신호를 추출하는 작업 중에 MFCC라는 결과물이 나오는데 이 MFCC를 학습에 사용하는 인식을 많이 사용합니다
MFCC 과정은 다음과 같다고 합니다.
.png)
위 블락도에 대해서 조사한 내용을 기록합니다.
PreEmphasis는 우리 음성 중에 높은 음들을 강조하도록 1st Order HPF를 처리하는 단계입니다.(연구에 따르면 고주파 성분이 일반적으로 크기가 작아서 조금 키워주면 음성인식 성능이 개선된다고 합니다.) Hamming Window와 FFT는 시간영역에서의 입력 신호를 주파수 영역으로 변환하는 과정입니다.(윈도우처리는 신호 왜곡을 막기 위해 처리하는 전처리입니다. 윈도우처리에 문제가 있으면 결과 주파수가 정확하지 않을 가능성이 높습니다. 윈도우 종류도 여러가지인데 사용해보고 좀더 적절한 윈도우를 선택한다면 주파수 결과가 더 잘 나올 때가 있습니다.) 이로써 의미있는 주요 주파수 성분에 대한 해석이 가능해 집니다. 이를 spectrum이라고 부릅니다. (참고로 Spectrum analyzer라는 장비를 보신 분들은 여기까의 동작을 하는 장비라는 생각하시면 됩니다). spectrum에서는 어떤 주파수가 강한지 약한지를 알 수 있고 강한 성분에 대한 주파수만 추출하여 분리합니다. 이를 Cepstrum이라고 부릅니다.
Cepstrum에서 mel Filter Bank처리를 해서 Mel Spectrum을 만듭니다.
Mel Spectrum은 우리 귀가 저주파수(약 1Khz 미만)는 비교적 자세하게 주파수를 구분할 수 있는 반면에 높은 주파수는 구분에 어려움이 있다는 특징을 이용하여 주파수별로 다른 Filter를 적용하여 뽑아내는데 이때 적용하는 기법이 Filter Bank이고 Mel Scale 필터 수식으로 계산합니다. 이후 log를 취한 log-Mel-spectrum을 IFFT를 처리하면 MFCC가 구해집니다.
파이썬코드에서는 Librosa 라이브러리를 이용해서 간단하게 위 처리를 변환했지만 아쉽게도 FW에서는 위 과정을 모두 구현해서 MFCC를 뽑아낸 다음 우리의 CNN모델에 적용해야할 것입니다.
FW에서의 추가/변경된 내용은 다음과 같습니다.
- 사용할 기능 활성화
.png)
- Sensing1 소스 패키지에서 다음 코드들을 복사
.png)
.png)
- Compile 옵션 변경
정의값 추가

Path 추가/변경
.png)
- 추가코드
-DFSDM 클락 초기화 함수 추가
.png)
-DFSDM ISR 코드 추가
-Handler callback 함수들
.png)
-Handler 에서 사용할 버퍼링 함수
.png)
-FFT 처리 및 메모리 초기화 추가
-mic 초기화 함수들
.png)
-그외 ai_데이터 처리 함수 변경

.png)
Ai 처리 함수
.png)
위 코드에서 acquire_and_process_data()함수는 모든 데이터가 샘플링되면 전처리를 수행하면 ai_in버퍼에 저장하고 ai_run으로 전달합니다. Ai_run에서는 우리의 model 결과를 처리할 것이고 data_outs버퍼로 결과가 전달됩니다.
- 실험.
학습 모델이 적용된 펌웨어를 실행해 보았습니다. 테스트 음성을 play하여 board에서 Mic로 입력된 음성을 샘플링하여 전처리한 데이타가 Ai모델로 처리되는 과정을 테스트했을 때 의미있는 결과값이 나오지 않았습니다.
모델학습 과정에서는 80%의 정확도라는 결과를 얻었지만 펌웨어까지 적용한 결과가 의미있는 결과를 얻지 못한 원인은 음성 데이터 전처리 데이타가 일치하지 않았기 때문이 아닐까 생각됩니다. Python model로의 입력치와 fw에서 model로의 입력 데이타가 서로 동일한 형태로 전처리된 것인지 정확한 확인이 이루어지지 못했기 때문에 그렇게 추정하고 있습니다. 시간이 더 있었다면 데이터 전처리 과정을 모두 디버깅 해봤을텐데 아쉽게도 시간내에 결과물을 내놓지 못했습니다.
- 과제 수행을 마무리하며…
비록 제대로된 결과는 내지 못했지만 음성 데이타셋 처리 과정을 통해 다음의 내용을
알게 되었습니다.
-음성의 주파수 변환(FFT)을 통한 주성분 분석(Spectrum 분석) 및 데이터 압축(Cepstrum분석) 후 주성분 음성만 재변환하여 비교 분석에 사용하는 방법(MFCC처리)
-CNN을 MFCC입력으로 학습했을 때 결과를 통해 데이터학습에 대한 지식
좀 더 펌웨어를 다듬어서 튜닝하지 못하고 마무리해야 되서 많이 아쉽지만 다음에는 좀 더 좋은 결과를 낼 수 있는 경험으로 삼고 마무리하며 기록을 마칩니다. 이렇게 좋은 이벤트를 기획해 주신 ST사에 감사의 말씀을 드리고 싶습니다.
이상입니다.
Tiel 작성.
- 첨부파일
- Final_Result_Q6_src_doc_tiel.zip 다운로드
로그인 후
참가 상태를 확인할 수 있습니다.